Stanbol Entityhub: Google Refine Reconciliation Support
This adds support for using the Stanbol Entityhub together with Google Refine for reconciliation of Entities.
Google Refine is a tool used to clean up messy data originating e.g. from lists managed with spread sheet tools, data base dumps ... The reconciliation steps allows than to link literal values of those data with Entities defined in some knowledge base - in this case Entities available via the Apache Stanbol Entityhub.
Google Refine Installation:
Configuring the Reconciliation Service
To configure a reconciliation service you need first to create a new (or open an existing) Google Refine Project. If you do not yet have an project you can use the ' book.scv' file included in the Apache Solr distribution to create a new one.
If you created a new Google Refine Project (e.g. by using the 'books.csv' example) you will see the imported data in tabular form. The following Screenshot visualises how to open the Reconciliation dialog for Book Authors.
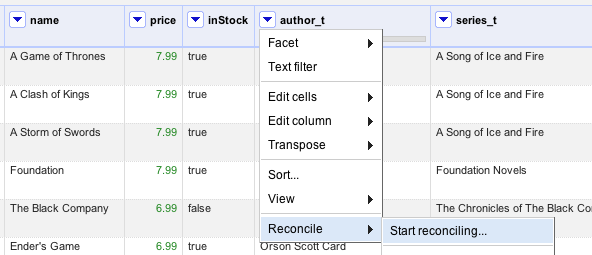
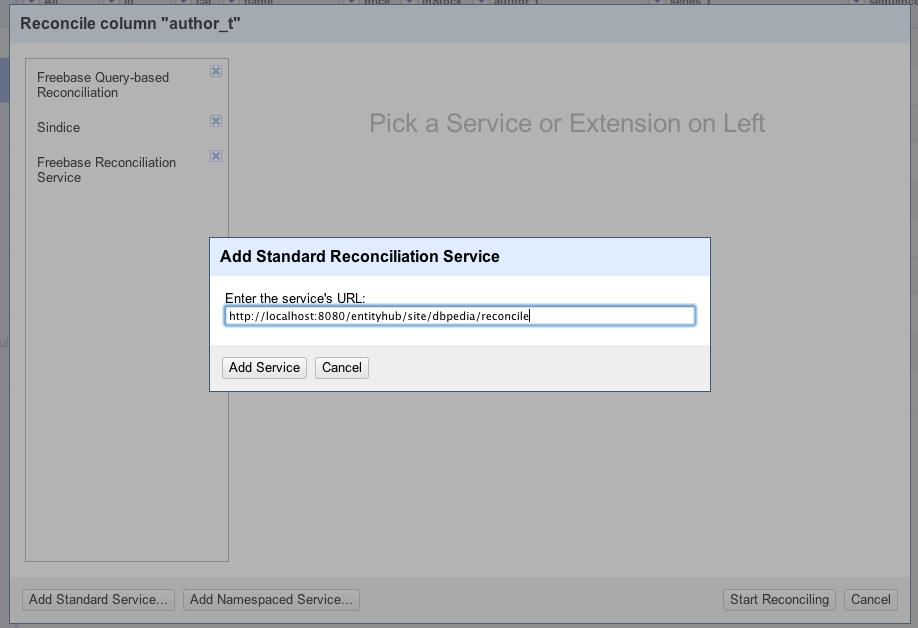
Via the Reconciliation dialog you can now "install" the Entityhub, Referenced Sites or the '/sites' endpoint as Standard Reconciliation Service by by pressing the [Add Standard Service ...] Button add copying the URL of this page to the dialog.
Service URL:
https://enrich.acdh.oeaw.ac.at/entityhub/reconcile
The following Screenshot shows how the install the Referenced Site for DBpedia.org.
Testing the Service
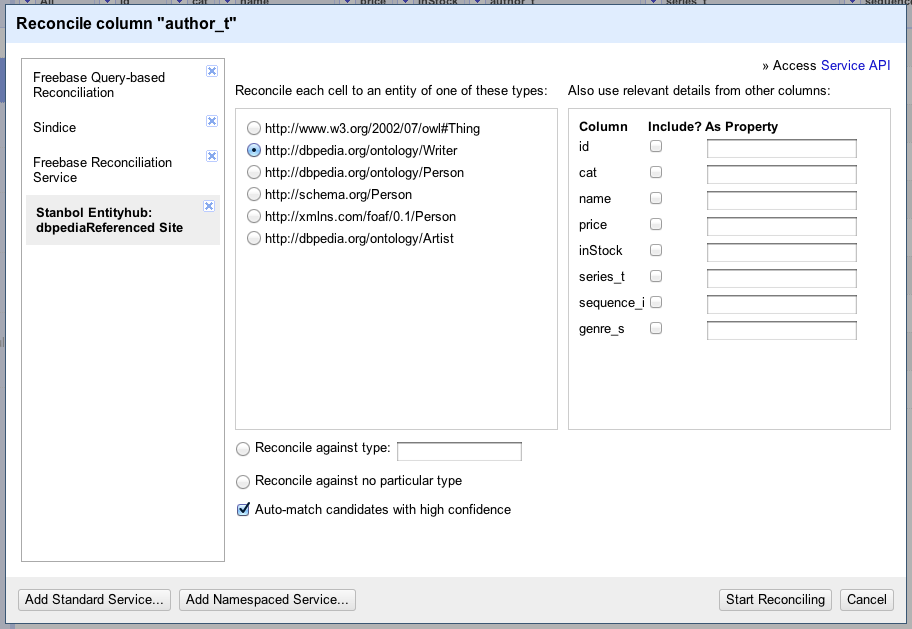
After this step a new Reconciliation Service will show up in the left link. In addition the newly installed site will be selected and used to provide suggestions for the initially selected column of you Google Refine project (Book Authors if you used the 'book.csv' sample data and selected the 'author_t' column).
The next Screenshot shows the installed Reconciliation service based on the Stanbol Entityhub: dbpedia Referenced Site that is ready to be used to reconcile Entities.
Usage of the Reconciliation Service
This provides first an overview about the usage of the Google Reconciliation service dialog and second the documentation of special features provided by this implementation.
Reconciliation Dialog
Reconciliation Dialog Fields
- Reconclie Services: On the left site the list of available Services is shown. As soon as you select one Google Refine will send a query of the first ten Entries of your current project to that service to obtain some meta data.
- Suggested Types:In the middle a list of suggested types is presented. This list will be empty if the service does not return any results for the request of the first ten entries. You can also manually add the type in the Field below the list. It is also possible to reconcile without constraining the type by selecting the last option.
- Using additional Properties: On the right side the list of all
columns of your project is shown. Information of those columns can be used to
for reconciliation. To use values of other columns the name of the property
must be specified on the text field next to the column name. The Stanbol
Entityhub also supports some special option like the semantic context-, full
text- and similarity-search (see below for details).
Note that it is possible to use the same property (and special fields) for mapping several columns. In this case values of all those columns are merged.
The Entityhub does support qnames (e.g. rdfs:label) for prefixes registered in the NamespaceEnum.
Special Property support
The Reconciliation Dialog allows to use values of other columns to improve reconciliation support. To further improve this ability the Stanbol Entityhub supports the following special fields:
- Full Text '
@fullText': This allows to use textual values of other fields to be matched against any textual value that is linked with suggested Entities (e.g. the values of rdfs:comment, skos:note, dbp-ont:abstract, ...). - Semantic Context '
@references': This allows to match the URI values of other columns (that are already reconciled) with suggested Entities. This is very useful to link further columns of an project if you have already reconciled (and possibly manually corrected/improved) an other column of the project. Note that this requires the dataset to define those links - Similarity Search '
@similarity': This will use textual values to rank returned values based on their similarity (using Solr MoreLikeThis).
By default this also uses the full text field however users can change this by explicitly parsing a {property} URI (or qname) '@similarity:{property}' as parameter. Note that parsed fields need to be correctly configured to support Solr MLT queries. The documentation of the Apache Entityhub Indexing Tool provides more information on that.
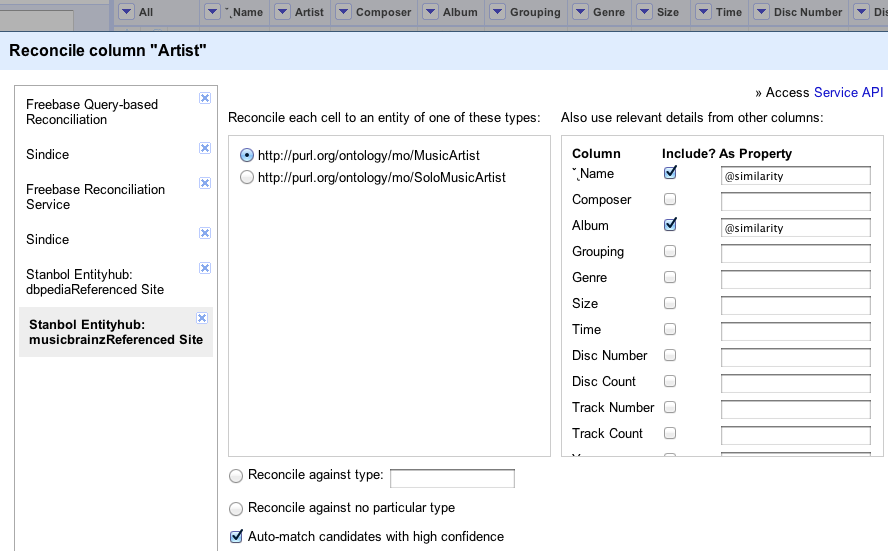
The following example shows how to use the '@similarity' for
disambiguating music artists based on the name of the track and the album. To
make this work the Musicbrainz was imported in the Entityhub in
a way that the labels of Albums and Tracks where indexed with the Artists.